I blogged about the Douglas-Rachford method before and in this post I’d like to dig a bit into the history of the method.
As the name suggests, the method has its roots in a paper by Douglas and Rachford and the paper is
Douglas, Jim, Jr., and Henry H. Rachford Jr., “On the numerical solution of heat conduction problems in two and three space variables.” Transactions of the American mathematical Society 82.2 (1956): 421-439.
At first glance, the title does not suggest that the paper may be related to monotone inclusions and if you read the paper you’ll not find any monotone operator mentioned. So let’s start and look at Douglas and Rachford’s paper.
1. Solving the heat equation numerically
So let us see, what they were after and how this is related to what is known as Douglas-Rachford splitting method today.
Indeed, Douglas and Rachford wanted to solve the instationary heat equation

with Dirichlet boundary conditions (they also considered three dimensions, but let us skip that here). They considered a rectangular grid and a very simple finite difference approximation of the second derivatives, i.e.

(with modifications at the boundary to accomodate the boundary conditions). To ease notation, we abbreviate the difference quotients as operators (actually, also matrices) that act for a fixed time step
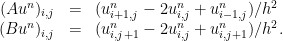
With this notation, our problem is to solve

in time.
Then they give the following iteration:


(plus boundary conditions which I’d like to swipe under the rug here). If we eliminate  from the first equation using the second we get
from the first equation using the second we get

This is a kind of implicit Euler method with an additional small term 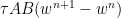 . From a numerical point of it has one advantage over the implicit Euler method: As equations (1) and (2) show, one does not need to invert
. From a numerical point of it has one advantage over the implicit Euler method: As equations (1) and (2) show, one does not need to invert  in every iteration, but only
in every iteration, but only  and
and  . Remember, this was in 1950s, and solving large linear equations was a much bigger problem than it is today. In this specific case of the heat equation, the operators
. Remember, this was in 1950s, and solving large linear equations was a much bigger problem than it is today. In this specific case of the heat equation, the operators  and
and  are in fact tridiagonal, and hence, solving with and can be done by Gaussian elimination without any fill-in in linear time (read Thomas algorithm). This is a huge time saver when compared to solving with which has a fairly large bandwidth (no matter how you reorder).
are in fact tridiagonal, and hence, solving with and can be done by Gaussian elimination without any fill-in in linear time (read Thomas algorithm). This is a huge time saver when compared to solving with which has a fairly large bandwidth (no matter how you reorder).
How do they prove convergence of the method? They don’t since they wanted to solve a parabolic PDE. They were after stability of the scheme, and this can be done by analyzing the eigenvalues of the iteration. Since the matrices and are well understood, they were able to write down the eigenfunctions of the operator associated to iteration (3) explicitly and since the finite difference approximation is well understood, they were able to prove approximation properties. Note that the method can also be seen, as a means to calculate the steady state of the heat equation.
We reformulate the iteration (3) further to see how  is actually derived from
is actually derived from 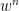 : We obtain
: We obtain

2. What about monotone inclusions?
What has the previous section to do with solving monotone inclusions? A monotone inclusion is
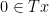
with a monotone operator, that is, a multivalued mapping  from a Hilbert space
from a Hilbert space  to (subsets of) itself such that for all
to (subsets of) itself such that for all 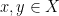 and
and 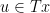 and
and  it holds that
it holds that
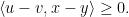
We are going to restrict ourselves to real Hilbert spaces here. Note that linear operators are monotone if they are positive semi-definite and further note that monotone linear operators need not to be symmetric. A general approach to the solution of monotone inclusions are so-called splitting methods. There one splits additively 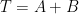 as a sum of two other monotone operators. Then one tries to use the so-called resolvents of and , namely
as a sum of two other monotone operators. Then one tries to use the so-called resolvents of and , namely

to obtain a numerical method. By the way, the resolvent of a monotone operator always exists and is single valued (to be honest, one needs a regularity assumption here, namely one need maximal monotone operators, but we will not deal with this issue here).
The two operators  and
and  from the previous section are not monotone, but
from the previous section are not monotone, but  and
and  are, so the equation
are, so the equation  is a special case of a montone inclusion. To work with monotone operators we rename
is a special case of a montone inclusion. To work with monotone operators we rename

and write the iteration~(4) in terms of monotone operators as

i.e.

Using  and
and 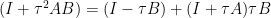 we rewrite this in terms of resolvents as
we rewrite this in terms of resolvents as
![\displaystyle \begin{array}{rcl} w^{n+1} & = &(I+\tau B)^{-1}[(I+\tau A)^{-1}(I-\tau B) + \tau B]w^{n}\\ & =& R_{\tau B}(R_{\tau A}(w^{n}-\tau Bw^{n}) + \tau Bw^{n}). \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+w%5E%7Bn%2B1%7D+%26+%3D+%26%28I%2B%5Ctau+B%29%5E%7B-1%7D%5B%28I%2B%5Ctau+A%29%5E%7B-1%7D%28I-%5Ctau+B%29+%2B+%5Ctau+B%5Dw%5E%7Bn%7D%5C%5C+%26+%3D%26+R_%7B%5Ctau+B%7D%28R_%7B%5Ctau+A%7D%28w%5E%7Bn%7D-%5Ctau+Bw%5E%7Bn%7D%29+%2B+%5Ctau+Bw%5E%7Bn%7D%29.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
This is not really applicable to a general monotone inclusion since there and may be multi-valued, i.e. the term  is not well defined (the iteration may be used as is for splittings where is monotone and single valued, though).
is not well defined (the iteration may be used as is for splittings where is monotone and single valued, though).
But what to do, when both and and are multivaled? The trick is, to introduce a new variable  . Plugging this in throughout leads to
. Plugging this in throughout leads to

We cancel the outer  and use
and use  to get
to get

and here we go: This is exactly what is known as Douglas-Rachford method (see the last version of the iteration in my previous post). Note that it is not 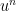 that converges to a solution, but
that converges to a solution, but  , so it is convenient to write the iteration in the two variables
, so it is convenient to write the iteration in the two variables

The observation, that these splitting method that Douglas and Rachford devised for linear problems has a kind of much wider applicability is due to Lions and Mercier and the paper is
Lions, Pierre-Louis, and Bertrand Mercier. “Splitting algorithms for the sum of two nonlinear operators.” SIAM Journal on Numerical Analysis 16.6 (1979): 964-979.
Other, much older, splitting methods for linear systems, such as the Jacobi method, the Gauss-Seidel method used different properties of the matrices such as the diagonal of the matrix or the upper and lower triangluar parts and as such, do not generalize easily to the case of operators on a Hilbert space.
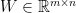
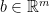
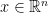

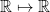
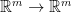


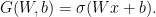

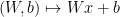
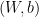
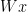

![{W = [w_{1}\ \cdots\ w_{n}]}](https://s0.wp.com/latex.php?latex=%7BW+%3D+%5Bw_%7B1%7D%5C+%5Ccdots%5C+w_%7Bn%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
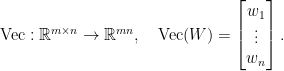
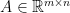
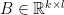



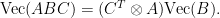
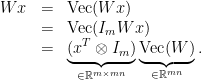
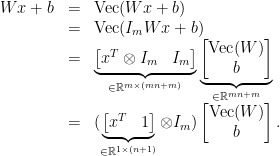
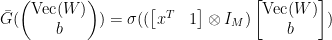
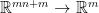
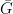
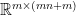
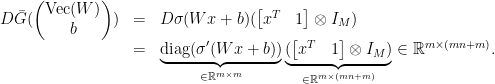


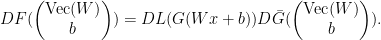
![\displaystyle \begin{array}{rcl} \nabla F( \begin{pmatrix} \mathrm{Vec}(W)\\b \end{pmatrix}) &=& D\bar G( \begin{pmatrix} \mathrm{Vec}(W)\\b \end{pmatrix})^{T} DL(G(Wx+b))^{T}\\ &=& ([x^{T}\ 1]\otimes I_{m})^{T}\mathrm{diag}(\sigma'(Wx+b))\nabla L(G(Wx+b))\\ &=& \underbrace{( \begin{bmatrix} x\\ 1 \end{bmatrix} \otimes I_{m})}_{\in{\mathbb R}^{(mn+m)\times m}}\underbrace{\mathrm{diag}(\sigma'(Wx+b))}_{\in{\mathbb R}^{m\times m}}\underbrace{\nabla L(G(Wx+b))}_{\in{\mathbb R}^{m}}. \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5Cbegin%7Barray%7D%7Brcl%7D++%5Cnabla+F%28+%5Cbegin%7Bpmatrix%7D+%5Cmathrm%7BVec%7D%28W%29%5C%5Cb+%5Cend%7Bpmatrix%7D%29+%26%3D%26+D%5Cbar+G%28+%5Cbegin%7Bpmatrix%7D+%5Cmathrm%7BVec%7D%28W%29%5C%5Cb+%5Cend%7Bpmatrix%7D%29%5E%7BT%7D+DL%28G%28Wx%2Bb%29%29%5E%7BT%7D%5C%5C+%26%3D%26+%28%5Bx%5E%7BT%7D%5C+1%5D%5Cotimes+I_%7Bm%7D%29%5E%7BT%7D%5Cmathrm%7Bdiag%7D%28%5Csigma%27%28Wx%2Bb%29%29%5Cnabla+L%28G%28Wx%2Bb%29%29%5C%5C+%26%3D%26+%5Cunderbrace%7B%28+%5Cbegin%7Bbmatrix%7D+x%5C%5C+1+%5Cend%7Bbmatrix%7D+%5Cotimes+I_%7Bm%7D%29%7D_%7B%5Cin%7B%5Cmathbb+R%7D%5E%7B%28mn%2Bm%29%5Ctimes+m%7D%7D%5Cunderbrace%7B%5Cmathrm%7Bdiag%7D%28%5Csigma%27%28Wx%2Bb%29%29%7D_%7B%5Cin%7B%5Cmathbb+R%7D%5E%7Bm%5Ctimes+m%7D%7D%5Cunderbrace%7B%5Cnabla+L%28G%28Wx%2Bb%29%29%7D_%7B%5Cin%7B%5Cmathbb+R%7D%5E%7Bm%7D%7D.+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)

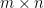




 and
and 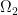 , coming with two measures
, coming with two measures 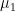 and
and 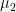 . We also have a function
. We also have a function 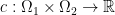 which assigns a transport cost, i.e.
which assigns a transport cost, i.e.  is the cost that it takes to carry one unit of mass from point
is the cost that it takes to carry one unit of mass from point  to
to 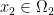 . What we want is a plan that says where the mass in
. What we want is a plan that says where the mass in 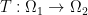 which says that thet mass in
which says that thet mass in  should be moved to
should be moved to 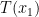 . While natural, there is a serious problem with this: What if not all mass at
. While natural, there is a serious problem with this: What if not all mass at 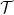 which map points in
which map points in 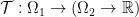 where
where 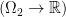 stands for some set of functions on
stands for some set of functions on 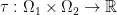 by
by  . That’s good in principle, be we still run into problems when the target mass distribution
. That’s good in principle, be we still run into problems when the target mass distribution  on
on 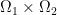 we look for a measure
we look for a measure  on
on 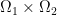 as a transport plan.
as a transport plan.
 it holds that
it holds that 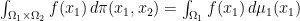 ).
).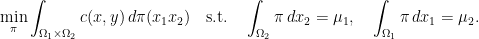
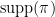 of
of  -cyclically monotone.
-cyclically monotone. such that its
such that its 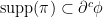 .
.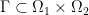 is
is 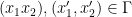 it holds that
it holds that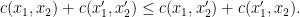
 and let
and let  be the usual scalar product. Then
be the usual scalar product. Then 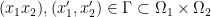 it holds that
it holds that
 somehow “moves up in
somehow “moves up in  ,
, 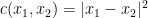 (
( being the euclidean norm) seems more natural, right? But if we have a transport plan
being the euclidean norm) seems more natural, right? But if we have a transport plan 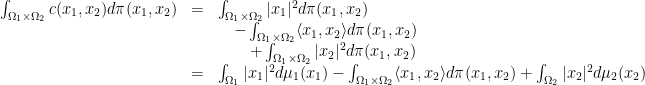
 is
is 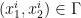 ,
,  and all permutations
and all permutations 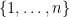 it holds that
it holds that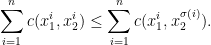
 we get back the notion of
we get back the notion of 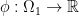 is
is 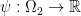 such that
such that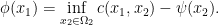
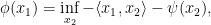

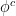 is the
is the 
 and a permutation
and a permutation 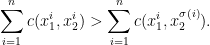
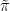 such that
such that 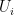 of
of 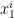 and
and 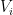 of
of 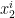 such that for all
such that for all 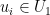 and
and 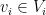 it holds that
it holds that
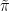 : Take the mass of
: Take the mass of  and shift it around. The full construction is a little messy to write down: Define a probability measure
and shift it around. The full construction is a little messy to write down: Define a probability measure  on the product
on the product 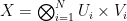 as the product of the measures
as the product of the measures 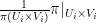 . Now let
. Now let 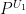 and
and  be the projections of
be the projections of 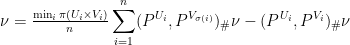
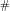 denotes the
denotes the 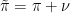 fulfills
fulfills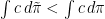
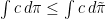 . By definition of the
. By definition of the 
 by assumption, this gives
by assumption, this gives

 -Lipschitz +
-Lipschitz +  -strongly monotone, the iteration with stepsize
-strongly monotone, the iteration with stepsize  converges linear with rate
converges linear with rate
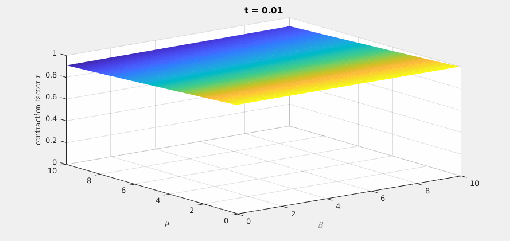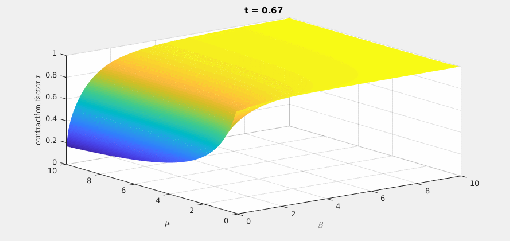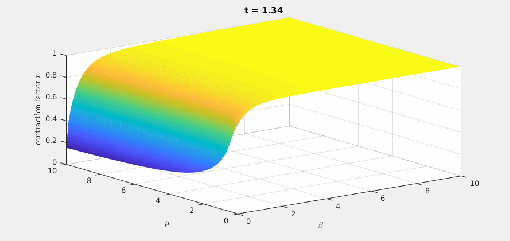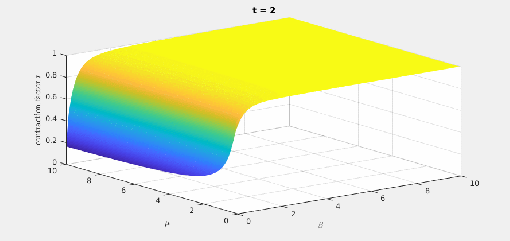
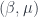 there is a best
there is a best 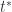 and also a smallest contraction factor
and also a smallest contraction factor  . Here are plots of these quantities:
. Here are plots of these quantities: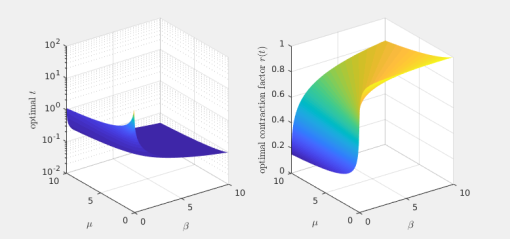
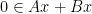
 from a Hilbert space into itself. Using the resolvent
from a Hilbert space into itself. Using the resolvent 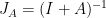 and the reflector
and the reflector 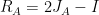 , the Douglas-Rachford iteration is concisely written as
, the Douglas-Rachford iteration is concisely written as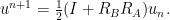
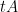 is monotone if
is monotone if 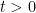 , we can introduce a stepsize for the Douglas-Rachford iteration
, we can introduce a stepsize for the Douglas-Rachford iteration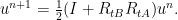
 and
and  -strongly monotone, than the Douglas-Rachford iterates converge strongly to a solution with a linear rate
-strongly monotone, than the Douglas-Rachford iterates converge strongly to a solution with a linear rate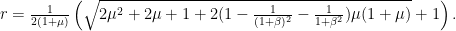


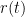 to get on optimal stepsize (in the sense that the guaranteed contraction factor is as small as possible). As Moursi and Vandenberghe explain in their Remark 5.4, this optimization involves finding the root of a polynomial of degree 5, so it is possible but cumbersome.
to get on optimal stepsize (in the sense that the guaranteed contraction factor is as small as possible). As Moursi and Vandenberghe explain in their Remark 5.4, this optimization involves finding the root of a polynomial of degree 5, so it is possible but cumbersome.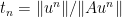 in the case of single valued
in the case of single valued 




 )
) 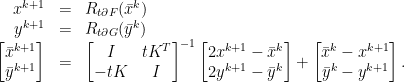
 as follows: The linear system equals
as follows: The linear system equals 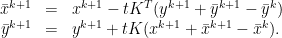
 from the second equation into the first gives
from the second equation into the first gives 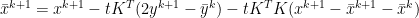
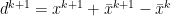 this can be written as
this can be written as 

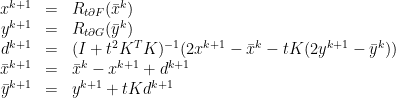

 is the image gradient, for example, we only need to solve an equation with an operator like
is the image gradient, for example, we only need to solve an equation with an operator like 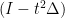 and appropriate boundary conditions). However, there are problems where this inversion is a problem.
and appropriate boundary conditions). However, there are problems where this inversion is a problem.
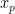 , which is forced to be zero by the additional indicator functional
, which is forced to be zero by the additional indicator functional  . Hence, the additional bilinear term
. Hence, the additional bilinear term  is also zero, and we see that
is also zero, and we see that 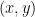 is a solution of
is a solution of  is a solution of
is a solution of 


 ,
, 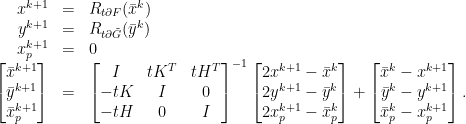
 throughout the iteration and from the last line of the linear system we get that
throughout the iteration and from the last line of the linear system we get that 

 and
and  disappear in the iteration. Now we rewrite the remaining first two lines of the linear system as
disappear in the iteration. Now we rewrite the remaining first two lines of the linear system as 
 , solving the second equation for
, solving the second equation for 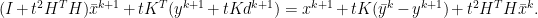
 we add
we add  on both sides and get
on both sides and get 
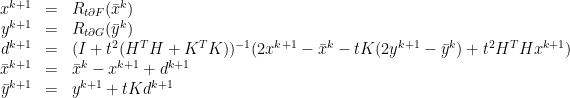
 , we have a lot of freedom. Let us see, that it is even possible to avoid any inversion whatsoever: We would like to choose
, we have a lot of freedom. Let us see, that it is even possible to avoid any inversion whatsoever: We would like to choose 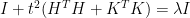 for some positive
for some positive  . This is equivalent to
. This is equivalent to 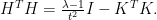
 . Further note, that we do need
. Further note, that we do need  , and we can perform the iteration without ever solving any linear system since the third row reads as
, and we can perform the iteration without ever solving any linear system since the third row reads as 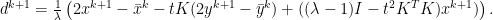

 and
and 
 is both primal and dual optimal if and only if the primal dual gap is zero, i.e. if and only if
is both primal and dual optimal if and only if the primal dual gap is zero, i.e. if and only if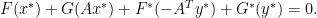
 and dual iterates
and dual iterates  one can monitor
one can monitor
 is actually
is actually  . This may be the case if
. This may be the case if 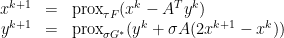
 .
. and
and  are always finite (since always
are always finite (since always  ), is may be that
), is may be that  or
or 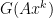 are indeed infinite, rendering the primal dual gap useless.
are indeed infinite, rendering the primal dual gap useless.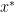 , i.e. a bounded and convex set
, i.e. a bounded and convex set 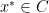 . In fact, this is often the case (e.g. one may know a-priori that there exist lower bounds
. In fact, this is often the case (e.g. one may know a-priori that there exist lower bounds  and upper bounds
and upper bounds  , i.e. it holds that
, i.e. it holds that  ). Then, adding these constraints to the problem will not change the solution.
). Then, adding these constraints to the problem will not change the solution.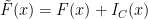 where
where 
 . This leads to a finite duality gap. However, one should also adapt the prox operator. But this is also simple in the case where the constraint
. This leads to a finite duality gap. However, one should also adapt the prox operator. But this is also simple in the case where the constraint ![{C = [l_{1},u_{1}]\times\cdots\times [l_{n},u_{n}]}](https://s0.wp.com/latex.php?latex=%7BC+%3D+%5Bl_%7B1%7D%2Cu_%7B1%7D%5D%5Ctimes%5Ccdots%5Ctimes+%5Bl_%7Bn%7D%2Cu_%7Bn%7D%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) ) and
) and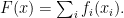
![\displaystyle \begin{array}{rcl} \mathrm{prox}_{\sigma \tilde F}(x)_{i} = \mathrm{prox}_{\sigma f_{i} + I_{[l_{i},u_{i}]}}(x_{i}) \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+%5Cmathrm%7Bprox%7D_%7B%5Csigma+%5Ctilde+F%7D%28x%29_%7Bi%7D+%3D+%5Cmathrm%7Bprox%7D_%7B%5Csigma+f_%7Bi%7D+%2B+I_%7B%5Bl_%7Bi%7D%2Cu_%7Bi%7D%5D%7D%7D%28x_%7Bi%7D%29+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle \begin{array}{rcl} \mathrm{prox}_{\sigma f_{i} + I_{[l_{i},u_{i}]}}(x_{i}) = \mathrm{proj}_{[l_{i},u_{i}]}\mathrm{prox}_{\tau f_{i}}(x_{i}), \end{array}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cbegin%7Barray%7D%7Brcl%7D+%5Cmathrm%7Bprox%7D_%7B%5Csigma+f_%7Bi%7D+%2B+I_%7B%5Bl_%7Bi%7D%2Cu_%7Bi%7D%5D%7D%7D%28x_%7Bi%7D%29+%3D+%5Cmathrm%7Bproj%7D_%7B%5Bl_%7Bi%7D%2Cu_%7Bi%7D%5D%7D%5Cmathrm%7Bprox%7D_%7B%5Ctau+f_%7Bi%7D%7D%28x_%7Bi%7D%29%2C+%5Cend%7Barray%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
 denoising which can be written as
denoising which can be written as
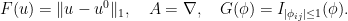
 which is an indicator functional and indeed
which is an indicator functional and indeed  will usually be dual infeasible. But since
will usually be dual infeasible. But since  is an image with a know range of gray values one can simple add the constraints
is an image with a know range of gray values one can simple add the constraints  to the problem and obtains a finite dual while still keeping a simple proximal operator. It is quite instructive to compute
to the problem and obtains a finite dual while still keeping a simple proximal operator. It is quite instructive to compute  in this case.
in this case. -Minimization with
-Minimization with  -Constraints
-Constraints
 constraint has been addressed quite often (and the penalized problem
constraint has been addressed quite often (and the penalized problem 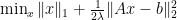 is even more popular) there is not much code around to solve this specific problem. Obvious candidates are
is even more popular) there is not much code around to solve this specific problem. Obvious candidates are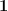 as
as 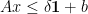 ,
, 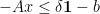 ) and for the objective one can, for example, perform a variable split
) and for the objective one can, for example, perform a variable split 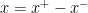 ,
,  and then write
and then write 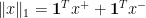 .
.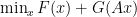 with
with

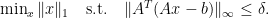
 is zero and that the set of solutions
is zero and that the set of solutions  , parameterized by the parameter
, parameterized by the parameter 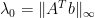 , calculate which direction to go, how far the breakpoint is away, go there and start over. I’ve blogged on the homotopy method
, calculate which direction to go, how far the breakpoint is away, go there and start over. I’ve blogged on the homotopy method 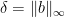 ,
,  is a solution. It is also not so difficult to see that there is a piecewise linear path of solutions
is a solution. It is also not so difficult to see that there is a piecewise linear path of solutions 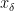 . What is not so clear is, how it can be computed. It turned out, that in this case the whole truth can be seen when the problem is viewed from a primal-dual viewpoint. The associated dual problem is
. What is not so clear is, how it can be computed. It turned out, that in this case the whole truth can be seen when the problem is viewed from a primal-dual viewpoint. The associated dual problem is

 denotes the sign function, multivalued at zero, giving
denotes the sign function, multivalued at zero, giving ![{[-1,1]}](https://s0.wp.com/latex.php?latex=%7B%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) there). One can note some things from the primal-dual optimality system:
there). One can note some things from the primal-dual optimality system: such that
such that 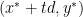 stays primal-dual optimal for the constraint
stays primal-dual optimal for the constraint 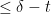 for small
for small  ,
,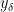 .
.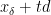 with stay primal optimal when reducing
with stay primal optimal when reducing  . In fact, it turned out that, at a breakpoint, a new dual variable needs to be found to allow for the next jump in the primal variable. So, the solution path is piecewise linear in the primal variable, but piecewise constant in the dual variable (a situation similar to the
. In fact, it turned out that, at a breakpoint, a new dual variable needs to be found to allow for the next jump in the primal variable. So, the solution path is piecewise linear in the primal variable, but piecewise constant in the dual variable (a situation similar to the  such that a jump in
such that a jump in 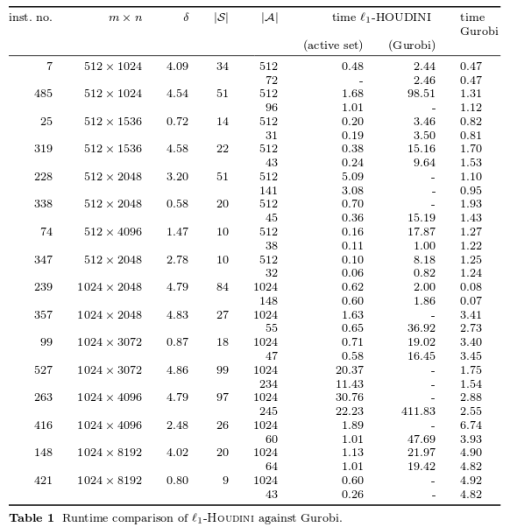
 -Houdini is on
-Houdini is on 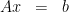

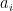 is the
is the  -th row of
-th row of 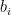 is the
is the 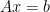 whenever the system has a solution. Moreover, it easy to see that we converge to the minimum norm solution in case of underdetermined systems when the method is initialized with zero. This is due to the fact that the whole iteration takes place in the range space of
whenever the system has a solution. Moreover, it easy to see that we converge to the minimum norm solution in case of underdetermined systems when the method is initialized with zero. This is due to the fact that the whole iteration takes place in the range space of  .
.
 is the soft thresholding function. In
is the soft thresholding function. In 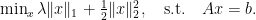
 solution.
solution.
