The mother example of optimization is to solve problems
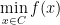
for functions 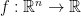 and sets
and sets 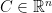 . One further classifies problems according to additional properties of
. One further classifies problems according to additional properties of  and
and  : If
: If  one speaks of unconstrained optimization, if is smooth one speaks of smooth optimization, if and are convex one speaks of convex optimization and so on.
one speaks of unconstrained optimization, if is smooth one speaks of smooth optimization, if and are convex one speaks of convex optimization and so on.
1. Classification, goals and accuracy
Usually, optimization problems do not have a closed form solution. Consequently, optimization is not primarily concerned with calculating solutions to optimization problems, but with algorithms to solve them. However, having a convergent or terminating algorithm is not fully satisfactory without knowing an upper bound on the runtime. There are several concepts one can work with in this respect and one is the iteration complexity. Here, one gives an upper bound on the number of iterations (which are only allowed to use certain operations such as evaluations of the function , its gradient 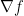 , its Hessian, solving linear systems of dimension
, its Hessian, solving linear systems of dimension  , projecting onto , calculating halfspaces which contain , or others) to reach a certain accuracy. But also for the notion of accuracy there are several definitions:
, projecting onto , calculating halfspaces which contain , or others) to reach a certain accuracy. But also for the notion of accuracy there are several definitions:
- For general problems one can of course desire to be within a certain distance to the optimal point
 , i.e.
, i.e. 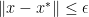 for the solution and a given point
for the solution and a given point  .
.
- One could also demand that one wants to be at a point which has a function value close to the optimal one
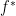 , i.e,
, i.e,  . Note that for this and for the first point one could also desire relative accuracy.
. Note that for this and for the first point one could also desire relative accuracy.
- For convex and unconstrained problems, one knowns that the inclusion
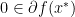 (with the subgradient
(with the subgradient  ) characterizes the minimizers and hence, accuracy can be defined by desiring that
) characterizes the minimizers and hence, accuracy can be defined by desiring that  .
.
It turns out that the first two definitions of accuracy are much to hard to obtain for general problems and even for smooth and unconstrained problems. The main issue is that for general functions one can not decide if a local minimizer is also a solution (i.e. a global minimizer) by only considering local quantities. Hence, one resorts to different notions of accuracy, e.g.
- For a smooth, unconstrained problems aim at stationary points, i.e. find such that
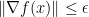 .
.
- For smoothly constrained smooth problems aim at “approximately KKT-points” i.e. a point that satisfies the Karush-Kuhn-Tucker conditions approximately.
(There are adaptions to the nonsmooth case that are in the same spirit.) Hence, it would be more honest not write  in these cases since this is often not really the problem one is interested in. However, people write “solve ” all the time even if they only want to find “approximately stationary points”.
in these cases since this is often not really the problem one is interested in. However, people write “solve ” all the time even if they only want to find “approximately stationary points”.
2. The gradient method for smooth, unconstrainted optimization
Consider a smooth function 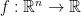 (we’ll say more precisely how smooth in a minute). We make no assumption on convexity and hence, we are only interested in finding stationary points. From calculus in several dimensions it is known that
(we’ll say more precisely how smooth in a minute). We make no assumption on convexity and hence, we are only interested in finding stationary points. From calculus in several dimensions it is known that 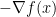 is a direction of descent from the point , i.e. there is a value
is a direction of descent from the point , i.e. there is a value 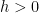 such that
such that 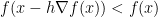 . Hence, it seems like moving into the direction of the negative gradient is a good idea. We arrive at what is known as gradient method:
. Hence, it seems like moving into the direction of the negative gradient is a good idea. We arrive at what is known as gradient method:
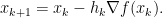
Now let’s be more specific about the smoothness of . Of course we need that is differentiable and we also want the gradient to be continuous (to make the evaluation of stable). It turns out that some more smoothness makes the gradient method more efficient, namely we require that the gradient of is Lipschitz continuous with a known Lipschitz constant  . The Lipschitz constant can be used to produce efficient stepsizes
. The Lipschitz constant can be used to produce efficient stepsizes  , namely, for
, namely, for 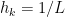 one has the estimate
one has the estimate
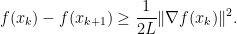
This inequality is really great because one can use telescoping to arrive at
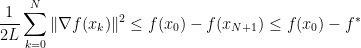
with the optimal value (note that we do not need to know for the following). We immediately arrive at
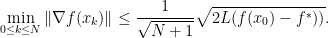
That’s already a result on the iteration complexity! Among the first  iterates there is one which has a gradient norm of order
iterates there is one which has a gradient norm of order 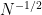 .
.
However, from here on it’s getting complicated: We can not say anything about the function values  and about convergence of the iterates
and about convergence of the iterates 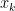 . And even for convex functions (which allow for more estimates from above and below) one needs some more effort to prove convergence of the functional values to the global minimal one.
. And even for convex functions (which allow for more estimates from above and below) one needs some more effort to prove convergence of the functional values to the global minimal one.
But how about convergence of the iterates for the gradient method if convexity is not given? It turns out that this is a hard problem. As illustration, consider the continuous case, i.e. a trajectory of the dynamical system
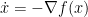
(which is a continuous limit of the gradient method as the stepsize goes to zero). A physical intuition about this dynamical system in 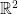 is as follows: The function describes a landscape and are the coordinates of an object. Now, if the landscape is slippery the object slides down the landscape and if we omit friction and inertia, the object will always slide in the direction of the negative gradient. Consider now a favorable situation: is smooth, bounded from below and the level sets
is as follows: The function describes a landscape and are the coordinates of an object. Now, if the landscape is slippery the object slides down the landscape and if we omit friction and inertia, the object will always slide in the direction of the negative gradient. Consider now a favorable situation: is smooth, bounded from below and the level sets 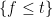 are compact. What can one say about the trajectories of the
are compact. What can one say about the trajectories of the  ? Well, it seems clear that one will arrive at a local minimum after some time. But with a little imagination one can see that the trajectory of does not even has to be of finite length! To see this consider a landscape that is a kind of bowl-shaped valley with a path which goes down the hillside in a spiral way such that it winds around the minimum infinitely often. This situation seems somewhat pathological and one usually does not expect situation like this in practice. If you tried to prove convergence of the iterates of gradient or subgradient descent you may have noticed that one sometimes wonders why the proof turns out to be so complicated. The reason lies in the fact that such pathological functions are not excluded. But what functions should be excluded in order to avoid this pathological behavior without restricting to too simple functions?
? Well, it seems clear that one will arrive at a local minimum after some time. But with a little imagination one can see that the trajectory of does not even has to be of finite length! To see this consider a landscape that is a kind of bowl-shaped valley with a path which goes down the hillside in a spiral way such that it winds around the minimum infinitely often. This situation seems somewhat pathological and one usually does not expect situation like this in practice. If you tried to prove convergence of the iterates of gradient or subgradient descent you may have noticed that one sometimes wonders why the proof turns out to be so complicated. The reason lies in the fact that such pathological functions are not excluded. But what functions should be excluded in order to avoid this pathological behavior without restricting to too simple functions?
3. The Kurdyka-Łojasiewicz inequality
Here comes the so-called Kurdyka-Łojasiewicz inequality into play. I do not know its history well, but if you want a pointer, you could start with the paper “On gradients of functions definable in o-minimal structures” by Kurdyka.
The inequality shall be a way to turn a complexity estimate for the gradient of a function into a complexity estimate for the function values. Hence, one would like to control the difference in functional value by the gradient. One way to do so is the following:
Definition 1 Let be a real valued function and assume (without loss of generality) that has a unique minimum at  and that
and that  . Then satisfies a Kurdyka-Łojasiewicz inequality if there exists a differentiable function
. Then satisfies a Kurdyka-Łojasiewicz inequality if there exists a differentiable function ![{\kappa:[0,r]\rightarrow {\mathbb R}}](https://s0.wp.com/latex.php?latex=%7B%5Ckappa%3A%5B0%2Cr%5D%5Crightarrow+%7B%5Cmathbb+R%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002) on some interval
on some interval ![{[0,r]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2Cr%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002) with
with  and
and 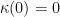 such that
such that
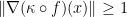
for all such that  .
.
Informally, this definition ensures that one can “reparameterize the range of the function such that the resulting function has a kink in the minimum and is steep around that minimum”. This definition is due to the above paper by Kurdyka from 1998. In fact it is a slight generalization of the Łowasiewicz inequality (which dates back to a note of Łojasiewicz from 1963) which states that there is some 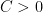 and some exponent
and some exponent  such that in the above situation it holds that
such that in the above situation it holds that
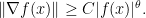
To see that, take 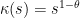 and evaluate the gradient to
and evaluate the gradient to 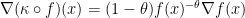 to obtain
to obtain  . This also makes clear that in the case the inequality is fulfilled, the gradient provides control over the function values.
. This also makes clear that in the case the inequality is fulfilled, the gradient provides control over the function values.
The works of Łojasiewicz and Kurdyka show that a large class of functions fulfill the respective inequalities, e.g. piecewise analytic function and even a larger class (termed o-minimal structures) which I haven’t fully understood yet. Since the Kurdyka-Łojasiewicz inequality allows to turn estimates from  into estimates of
into estimates of 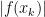 it plays a key role in the analysis of descent methods. It somehow explains, that one really never sees pathological behavior such as infinite minimization paths in practice. Lately there have been several works on further generalization of the Kurdyka-Łojasiewicz inequality to the non-smooth case, see e.g. Characterizations of Lojasiewicz inequalities: subgradient flows, talweg, convexity by Bolte, Daniilidis, Ley and Mazet Convergence of non-smooth descent methods using the Kurdyka-Łojasiewicz inequality by Noll (however, I do not try to give an overview over the latest developments here). Especially, here at the French-German-Polish Conference on Optimization which takes place these days in Krakow, the Kurdyka-Łojasiewicz inequality has popped up several times.
it plays a key role in the analysis of descent methods. It somehow explains, that one really never sees pathological behavior such as infinite minimization paths in practice. Lately there have been several works on further generalization of the Kurdyka-Łojasiewicz inequality to the non-smooth case, see e.g. Characterizations of Lojasiewicz inequalities: subgradient flows, talweg, convexity by Bolte, Daniilidis, Ley and Mazet Convergence of non-smooth descent methods using the Kurdyka-Łojasiewicz inequality by Noll (however, I do not try to give an overview over the latest developments here). Especially, here at the French-German-Polish Conference on Optimization which takes place these days in Krakow, the Kurdyka-Łojasiewicz inequality has popped up several times.

Leave a comment