Today I would like to comment on two arxiv-preprints I stumbled upon:
1. “Augmented L1 and Nuclear-Norm Models with a Globally Linearly Convergent Algorithm” – The Elastic Net rediscovered
The paper “Augmented L1 and Nuclear-Norm Models with a Globally Linearly Convergent Algorithm” by Ming-Jun Lai and Wotao Yin is another contribution to a field which is (or was?) probably the fastest growing field in applied mathematics: Algorithms for convex problems with non-smooth 
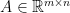


or, for 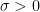
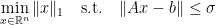
which appeared here on this blog previously. Although this is a convex problem and even has a reformulation as linear program, some instances of this problem are notoriously hard to solve and gained a lot of attention (because their applicability in sparse recovery and compressed sensing). Very roughly speaking, a part of its hardness comes from the fact that the problem is neither smooth nor strictly convex.
The contribution of Lai and Yin is that they analyze a slight perturbation of the problem which makes its solution much easier: They add another term in the objective; for 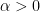
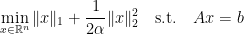
or

This perturbation does not make the problem smooth but renders it strongly convex (which usually makes the dual more smooth). It turns out that this perturbation makes life with this problem (and related ones) much easier – recovery guarantees still exists and algorithms behave better.
I think it is important to note that the “augmentation” of the 


I also worked on elastic-net problems for problems in the form
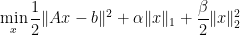
in this paper (doi-link). Here it also turns out that the problem gets much easier algorithmically. I found it very convenient to rewrite the elastic-net problem as

which turns the elastic-net problem into just another
2. Towards a Mathematical Theory of Super-Resolution
The second preprint is “Towards a Mathematical Theory of Super-Resolution” by Emmanuel Candes and Carlos Fernandez-Granda.
The idea of super-resolution seems to pretty old and, very roughly speaking, is to extract a higher resolution of a measured quantity (e.g. an image) than the measured data allows. Of course, in this formulation this is impossible. But often one can gain something by additional knowledge of the image. Basically, this also is the idea behind compressed sensing and hence, it does not come as a surprise that the results in compressed sensing are used to try to explain when super-resolution is possible.
The paper by Candes and Fernandez-Granada seems to be pretty close in spirit to Exact Reconstruction using Support Pursuit on which I blogged earlier. They model the sparse signal as a Radon measure, especially as a sum of Diracs. However, different from the support-pursuit-paper they use complex exponentials (in contrast to real polynomials). Their reconstruction method is basically the same as support pursuit: The try to solve
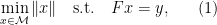
i.e. they minimize over the set of Radon measures 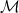
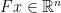

I want to add that the idea of “continuous sparse modelling” in the space of signed measures is very appealing to me and appeared first in Inverse problems in spaces of measures by Kristian Bredies and Hanna Pikkarainen.

April 2, 2012 at 10:18 pm
Interesting post.
There is a R package glmnet (http://cran.r-project.org/web/packages/glmnet/index.html) that implements elastic nets by Hastie team;
A detailed manual can be found here: http://www.jstatsoft.org/v33/i01 . Also, I think they call it elastic nets because geometric realization of the augmented problem may be scaled/stretched with changing the values of the parameters alpha and beta.
April 3, 2012 at 7:54 am
Thank you for the comments on the paper. It is perhaps worth noting that the optimization problem can be approximated by solving L1 norm minimization on a fine grid, for which a lot of off the shelf software is available. As you point out, this discretized setting is reminiscent of compressed sensing, although in this case the measurement matrix is deterministic and as a consequence previous results on L1 norm recovery do not apply or are very weak.
April 3, 2012 at 9:10 am
Indeed, approximating by discretizing to a fine grid is possible. Do you have some general rule how to choose the grid? And how does refinement of the discretization increase the problem size for l^1? In other words: Is is possible to control the computational complexity while approximating the measure-space-problem? I’d like to add that there are approaches to minimization problems in measure space without discretization of the underlying set, see the paper by Bredies and Pikkarainen I mentioned above and also work by Clason and Kunisch.
The deterministic measurement is a cool thing. Do you think that its ok to say that one can eliminate the randomness by making continuous measurements in that situation?
April 3, 2012 at 5:48 pm
The way the problem is discretized is quite application dependent. In the paper our aim was to establish precise guarantees on the super-resolution of point sources by solving convex programs, which were lacking in the literature, but it would certainly be interesting to explore the implementation details of the approach in different contexts.
The reason why one can eliminate the randomness both in the discrete and the continuous setting is that we are making an assumption on the signal to be recovered, namely that there is a minimum distance between the elements of its support. This distance is just two over the cut-off frequency of the measurement process (twice the smallest wavelength you get to see). Interestingly, if you have just a few point sources they cannot be much nearer either because the problem would become hopelessly ill-posed (we show this using Slepian’s prolate spheroidal sequences).
April 5, 2012 at 5:51 pm
The TV norm in that paper is also the gauge norm or the atomic norm of an infinite set of unit norm single frequency vectors. We show that this indeed is equivalent to sampling on a fine enough grid (and say how fine is enough for a given prediction accuracy), also give an exact SDP formulation, and give some stability results. For more details, see http://arxiv.org/abs/1204.0562
April 10, 2012 at 11:03 am
Thanks for pointing me to that paper! I did not fully get the meaning of your comment (probably due to some notational confusion). In your paper in section 3 you deal with the signal x*. Is that already discrete or is this a complex valued function on the real line? Put differently: Do you assume that the values u_l are known? And what about the number n? Is that number fixed? Sorry for my confusion…
April 10, 2012 at 12:30 pm
Hi Dirk, the notation is in Sec 1.1. $x^\star$ is a $C^n$ vector with $n$ uniform samples of the signal $x$. The normalized frequencies $u_l^\star$, the corresponding amplitudes $c_l^\star$ and their number $k$ are all unknown. The number of samples $n$ is fixed. I hope that clarifies it bit..